Introduction
We use the Java Stream’s reduce method to reduce a stream of values to a single result. There are three overloaded Stream#reduce operation. In this post, we will discuss all three variations of the overloaded Stream#reduce operation.
What is Reduction of a Java Stream
A reduction operation takes a sequence of input elements and combines them into a single summary result by repeated application of a combining operation. An example of this is finding the sum of a set of numbers where we start from a set of numbers and end up with a single result, which is the sum of all numbers. The reduction operation is also called as fold.
Why use Java Stream’s reduction over imperative reduction
If we take the previous example of summing the numbers, we can write a simple for-loop to loop through the input and do anything we want (sum in this case) to reduce the input. But when doing this using Streams, in some cases (depending on the number of elements and other factors), we can easily parallelize the reduction across multiple threads and thus gain an improvement in performance.
As we will see the, function which does the reduction computation will be required to have certain characteristics or properties viz., they have to be associative, stateless and non-interfering. Before looking at the Java Stream Reduce functions, let us understand what these properties mean.
Properties of a reduction function
Non-interference
This simply means that the function should not modify the original data source when it is being executed in the stream pipeline. There is some exception to this rule when the data source is one of the concurrent collections. However, in most cases, the functions should operate only on the input it gets and not interfere with the data source, i.e., shouldn’t modify the stream’s data source.
An example from the Stream package-summary Javadoc is below. It creates a stream from the collection and then adds an element to the original collection. Then, we use collect operation with Collectors.joining on the stream to collect the input elements. The result will have all the three elements joined together.
List<String> l = new ArrayList(Arrays.asList("one", "two"));
Stream<String> sl = l.stream();
l.add("three");
String s = sl.collect(joining(" "));
Quoting from the same package-summary Javadoc, such interference can result in exceptions or incorrect results and should be avoided in the functions we will use for reduction.
Modifying a stream’s data source during execution of a stream pipeline can cause exceptions, incorrect answers, or nonconformant behavior. For well-behaved stream sources, the source can be modified before the terminal operation commences and those modifications will be reflected in the covered elements.
Stateless
The intermediate operations can be stateful (like sorted) or stateless (filter, map). The reduction functions should be stateless, i.e., they shouldn’t have to remember any of the previous computation results.
An example in the Javadoc is,
Set<Integer> seen = Collections.synchronizedSet(new HashSet<>());
stream.parallel()
.map(e -> {
if (seen.add(e)) return 0;
else return e;
})...
Here, the mapping function writes data to an external collection. When we perform the computation on a parallel stream, the results could change from run to run. Hence, avoid the function being stateful.
Associativity
This is pretty straightforward. A function is associative if the following holds:
(a op b) op c == a op (b op c)
In parallel stream pipelines, we cannot determine the order in which the elements will be evaluated and hence we have the requirement for the reduction function to be associative.
Examples of associative operations are addition, min, and max, and string concatenation.
Java Stream Reduce operation
Let us now learn about the three varieties of Java Stream Reduce operation.
#1 - Reduce a Stream with an Identity element
This overload/variation of Stream#reduce takes an identity element and an accumulator function. The identity element is of the same type as the stream element (T) and the accumulator function is a BinaryOperator i.e., it is a BiFunction<T,T,T> (takes two arguments of type T and returns a result of the same type).
T reduce(T identity, BinaryOperator<T> accumulator)
It performs a reduction on the stream elements using the identity value and the accumulator.
- It starts with the result equal to the identity element.
- For each of the stream element, it calls the accumulator function passing the current result value and the stream element.
- Finally, it assigns the returned result (from the accumulator function) as the result.
It does this for all the stream elements. The final result is the reduced value.
This operation, when written in an imperative fashion, is equivalent to:
T result = identity;
for (each 'element' (of type T) in the stream) {
result = accumulator.apply(result, element)
}
return result;
Example of a Stream reduction with an identity element
Let us look at an example of using the above reduce operation on a Java stream.
We have a list of integers (List<Integer>) and we create a stream out of it and use the reduce operation on the stream to reduce the stream to an integer.
We have the value 0 as the identity value and the reduction function (accumulator) is the method reference Integer::sum. Its lambda equivalent is (a, b) -> a + b which is a BiFunction taking two Integer values and returning the sum of it. Thus, this Stream#reduce operation calculates the sum of all elements in the stream, resulting in a final reduced value of 15.
List<Integer> ints = List.of(1, 2, 3, 4, 5);
Integer sum = ints.stream()
.reduce(0, Integer::sum);
System.out.println(sum); //15
In case the stream becomes empty (or if we start with an empty stream), then the result of the reduction will be the identity value. As shown below, we can apply a filter condition to include only the elements in the stream whose value is greater than 10. Since none of the elements in the stream satisfy that condition, the reduction result is 0 (the sum of elements of an empty stream is 0).
System.out.println(ints.stream()
.filter(i -> i > 10)
.reduce(0, Integer::sum)); //0
Understanding the accumulator function
In the first example, we can add a print statement and observe how it is being called.
System.out.println(ints.stream()
.reduce(0,
(a, b) -> {
System.out.printf("Accumulating %d and %d in thread %s%n", a, b,
Thread.currentThread().getName());
return a + b;
}));
When we run this code, we get the following output:
Accumulating 0 and 1 in thread main
Accumulating 1 and 2 in thread main
Accumulating 3 and 3 in thread main
Accumulating 6 and 4 in thread main
Accumulating 10 and 5 in thread main
15
For better understanding, I have provided a pictorial representation of this below.
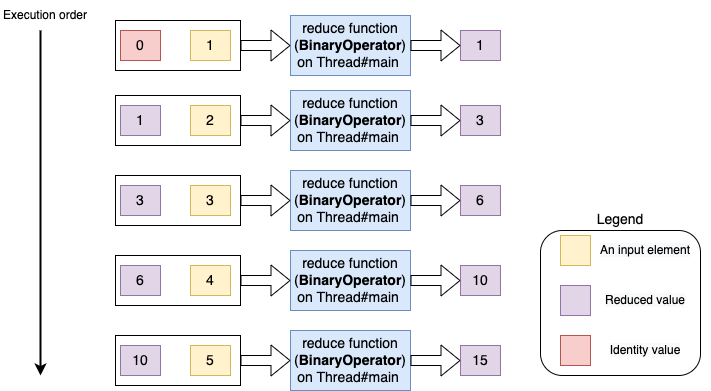
- First, it calls the accumulator function with the identity element (0) and the first element in the stream (1). The function returns the result of the sum of these two (1).
- Next, it calls the function with the previous result (which is the current sum, 1) and the next stream element (2). The function, as before, returns the sum of these (3).
- And so on… (it repeats the process for the rest of the elements in the stream).
- Finally, we have the reduced value, which is the sum of all the elements in the stream (which is 15).
As seen from the output, the reduction takes place on the main thread.
Predicates chaining - Example
This version of the Stream reduce is particularly helpful for chaining predicates. Let’s say we have the below representation of a Student (If you are new to records, check out the post on Java records).
record Student(String name, int age, List<String> courses) {}
Let’s create a list of student instances, as shown below.
List<Student> students = List.of(
new Student("S1", 18, List.of("CS", "Math")),
new Student("S2", 19, List.of("Math")),
new Student("S3", 22, List.of("CS")),
new Student("S4", 20, List.of("Physics", "CS"))
);
Now say we want to filter students who are over 20 and have “CS” as one of their courses. We can create a stream pipeline from the students list and apply this condition in the filter step. Since we have multiple conditions to apply, we can first chain the predicates using reduction.
We use Stream.reduce by writing a utility method which takes a var-args of Predicate<Student> and returns a single Predicate which composes all the passed predicates (which represents a short-circuiting logical AND of all the predicates).
//Unchecked generics array creation for varargs parameter
@SafeVarargs
private static Predicate<Student> and(Predicate<Student>... predicates) {
return Arrays.stream(predicates)
.reduce(student -> true, Predicate::and);
}
Here the accumulator function of the reduce takes two predicates and calls the Predicate#and i.e., (firstPredicate, secondPredicate) -> firstPredicate.and(secondPredicate). Since we are ‘AND’ing’ all predicates, the identity value is a predicate which returns true.
We can do the same with Predicate::or to compose passed predicates to represent a short-circuiting local OR of all the predicates.
@SafeVarargs
private static Predicate<Student> or(Predicate<Student>... predicates) {
return Arrays.stream(predicates)
.reduce(student -> false, Predicate::or);
}
Now, we can compose multiple predicates as,
Predicate<Student> isOverTwenty = student -> student.age() > 20;
Predicate<Student> studiesCS = student -> student.courses().contains("CS");
Predicate<Student> isOverTwentyAndStudiesCS = and(isOverTwenty, studiesCS);
System.out.println(students.stream()
.filter(isOverTwentyAndStudiesCS)
.collect(Collectors.toList())); //[Student[name=S3, age=22, courses=[CS]]]
When we run the above code, it returns only Student-3 (S3). Similarly, we can use the or predicate as,
Predicate<Student> isOverTwentyOrStudiesCS = or(isOverTwenty, studiesCS);
System.out.println(students.stream()
.filter(isOverTwentyOrStudiesCS)
.collect(Collectors.toList()));
Prints, (formatted for readability)
[
Student[name=S1, age=18, courses=[CS, Math]],
Student[name=S3, age=22, courses=[CS]],
Student[name=S4, age=20, courses=[Physics, CS]]
]
Stream Reduction in Parallel
Let us now run the reduction operation with a parallel stream. We can turn a stream into a parallel stream by adding parallel() to the chain of operations.
To make it simpler to visualize what is happening, let’s use a stream with only three elements for the reduction.
List<Integer> ints = List.of(1, 2, 3);
System.out.println(ints.stream()
.parallel()
.reduce(0,
(a, b) -> {
System.out.printf("Accumulating %d and %d in thread %s%n", a, b,
Thread.currentThread().getName());
return a + b;
}));
The only change from the previous code is the addition of .parallel(). Because the reduction happens in parallel, the output shown below is just one of the possible outputs that we could get.
Accumulating 0 and 2 in thread main
Accumulating 0 and 1 in thread ForkJoinPool.commonPool-worker-1
Accumulating 0 and 3 in thread ForkJoinPool.commonPool-worker-2
Accumulating 2 and 3 in thread ForkJoinPool.commonPool-worker-2
Accumulating 1 and 5 in thread ForkJoinPool.commonPool-worker-2
6
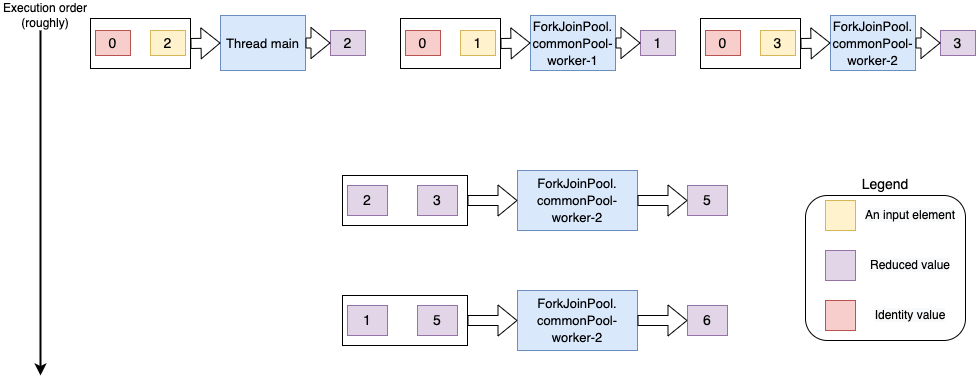
- The accumulation operation on the main thread took the identity element (0) and the input element (2) and returned 2 as the result.
- In parallel, two FookJoinPool worker threads were also used for the reduction operation. Each of these started with the identity value of 0 and two other input elements (1 and 3).
- Then the thread ForkJoinPool.commonPool-worker-2 did the computation for elements 2 and
- Finally, the same thread was used for computing the sum of 1 and 5.
Comparing this to our previous run of reducing a stream in sequence, we can see how multiple threads are used in parallel, where (in this case) each starting with a stream element and the identity value.
When we have five input elements, one possible output during the reduction is:
Accumulating 0 and 3 in thread main
Accumulating 0 and 1 in thread ForkJoinPool.commonPool-worker-1
Accumulating 0 and 2 in thread ForkJoinPool.commonPool-worker-2
Accumulating 1 and 2 in thread ForkJoinPool.commonPool-worker-2
Accumulating 0 and 4 in thread ForkJoinPool.commonPool-worker-3
Accumulating 0 and 5 in thread main
Accumulating 4 and 5 in thread main
Accumulating 3 and 9 in thread main
Accumulating 3 and 12 in thread main
15
A wrong choice of identity value
Note that the identity value must be an identity for the accumulator function. This means that accumulator.apply(identity, t) must be equal to t (where t is any stream element). For the addition operation, the identity value is 0.
If we use an incorrect (or inappropriate) identity value (let us say 1) with a sequential stream, the result of the reduction will be off by 1.
If we have a parallel stream, the result depends on how many parallel threads it uses to initiate the accumulation in parallel (i.e., the number of threads starting with the identity value and a stream element).
Example:
List<String> ints = List.of(1, 2, 3, 4, 5);
System.out.println(ints.stream()
.parallel()
.reduce(1,
(a, b) -> {
System.out.printf("Accumulating %d and %d in thread %s%n", a, b,
Thread.currentThread().getName());
return a + b;
}));
One possible output is:
Accumulating 1 and 3 in thread main
Accumulating 1 and 2 in thread ForkJoinPool.commonPool-worker-3
Accumulating 1 and 1 in thread ForkJoinPool.commonPool-worker-4
Accumulating 2 and 3 in thread ForkJoinPool.commonPool-worker-4
Accumulating 1 and 5 in thread ForkJoinPool.commonPool-worker-1
Accumulating 1 and 4 in thread ForkJoinPool.commonPool-worker-2
Accumulating 5 and 6 in thread ForkJoinPool.commonPool-worker-2
Accumulating 4 and 11 in thread ForkJoinPool.commonPool-worker-2
Accumulating 5 and 15 in thread ForkJoinPool.commonPool-worker-2
20
Using a non-associative accumulator function
If the accumulator function is not associative, the sequential reduction and parallel reduction will give different results. This violates one of the earlier stated requirements.
List<Integer> ints = List.of(2, 3, 4);
System.out.println(ints.stream()
.parallel()
.reduce(0,
(a, b) -> {
System.out.printf("Accumulating %d and %d in thread %s%n", a, b,
Thread.currentThread().getName());
return 2 * a + b;
}));
Accumulating 0 and 3 in thread main
Accumulating 0 and 2 in thread ForkJoinPool.commonPool-worker-2
Accumulating 0 and 4 in thread ForkJoinPool.commonPool-worker-1
Accumulating 3 and 4 in thread ForkJoinPool.commonPool-worker-1
Accumulating 2 and 10 in thread ForkJoinPool.commonPool-worker-1
14
In the above example, we got 14 as the result of using a non-associative function. If we run it with a sequential stream, we would get 18 as the result.
#2 - Stream reduction with just the accumulator function
The second version of the Stream#reduce takes only an accumulator function. It does the reduction on the stream elements in the same way as before, but without an identity value. Therefore, it returns an Optional result; If the reduction is performed on an empty stream, the optional will be empty. Otherwise, the optional will contain the reduced value.
Optional<T> reduce(BinaryOperator<T> accumulator)
This is equivalent to:
boolean foundAny = false;
T result = null;
for (each 'element' (of type T) in the stream) {
if (!foundAny) {
foundAny = true;
result = element;
}
else
result = accumulator.apply(result, element);
}
return foundAny ? Optional.of(result) : Optional.empty();
Example of a Stream reduction without an identity element
Let’s use the same example as before, but this time we don’t have an identity value. The result of the reduction is wrapped in an Optional.
List<Integer> ints = List.of(1, 2, 3, 4, 5);
Optional<Integer> sum = ints.stream()
.reduce(Integer::sum);
System.out.println(sum); //Optional[15]
In the example below, by applying the filter, we get an empty stream. As a result, the reduction returns an empty optional.
Optional<Integer> sum = ints.stream()
.filter(i -> i > 10)
.reduce(Integer::sum);
System.out.println(sum); //Optional.empty
#3 - Reducing a stream to a different type
The third version of the Stream#reduce operation takes three arguments and allows us to reduce a stream of values to a different type. As shown below, it takes an identity of type U, a BiFunction (which is the accumulator function as we’ve seen before), and a combiner function.
<U> U reduce(U identity,
BiFunction<U,? super T,U> accumulator,
BinaryOperator<U> combiner)
It reduces a stream having elements of type T to a single value of type U.
The accumulator function takes the current partial result of type U and a stream element and returns a value of type U. The combiner function is a BinaryOperator which is a BiFunction<T, T, T> i.e., it takes two arguments of type T and returns a value of the same type.
This is equivalent to,
U result = identity;
for (each 'element' (of type T) in the stream) {
result = accumulator.apply(result, element)
}
return result;
Note that as seen before the identity value must be an identity for the combiner function i.e., combiner(identity, u) must be equal to u. Additionally, the combiner function must be compatible with the accumulator function; for all elements u and t, the following must hold:
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
Example of reducing a stream to a different type
Let us reduce a stream of strings to an integer, which is the sum of the length of all the elements.
List<String> strings = List.of("ab", "c", "def", "ghij");
int length = strings.stream()
.reduce(0,
(res, s) -> res + s.length(),
Integer::sum); //(l1, l2) -> l1 + l2);
System.out.println(length); //10
We have:
- An identity value of 0
- An accumulator function, which takes an integer (partial) result and a string and adds the string’s length to it, returning the new result.
- The combiner function takes two partial results, adds them, and returns the result.
The result of running the above code will be 10.
What is the combiner function? How or when it would be called?
It would be used when we have a parallel stream (we will see this in a moment).
Before we convert the above stream to a parallel one, let us add print statements inside the accumulator and the combiner function.
System.out.println(strings.stream()
.reduce(0,
(res, s) -> {
System.out.printf("Accumulating %d and string '%s' in thread %s%n", res, s,
Thread.currentThread().getName());
return res + s.length();
},
(l1, l2) -> {
System.out.printf("Combining %d and %d in thread %s%n", l1, l2,
Thread.currentThread().getName());
return l1 + l2;
}));
Prints,
Accumulating 0 and string 'ab' in thread main
Accumulating 2 and string 'c' in thread main
Accumulating 3 and string 'def' in thread main
Accumulating 6 and string 'ghij' in thread main
10
When the stream is sequential, the combiner function won’t be used. The stream pipeline calls the accumulator function with the identity value 0 and the first string element in the stream and the function returns the sum of the identity value and the string’s length. Next, it gets called with the previous result and the second string from the stream and so on.
This is very similar to the first version of Stream#reduce we saw (which uses an identity value and an accumulator function), but this version allows us to reduce to a different type.
Stream reduction to a different type on a parallel stream
Let us take the same code as before and add parallel() to make the stream parallel and see how the output will change.
System.out.println(strings.stream()
.parallel()
.reduce(0,
(res, s) -> {
System.out.printf("Accumulating %d and string '%s' in thread %s%n", res, s,
Thread.currentThread().getName());
return res + s.length();
},
(l1, l2) -> {
System.out.printf("Combining %d and %d in thread %s%n", l1, l2,
Thread.currentThread().getName());
return l1 + l2;
}));
Prints,
Accumulating 0 and string 'def' in thread main
Accumulating 0 and string 'ab' in thread ForkJoinPool.commonPool-worker-2
Accumulating 0 and string 'ghij' in thread main
Accumulating 0 and string 'c' in thread ForkJoinPool.commonPool-worker-1
Combining 2 and 1 in thread ForkJoinPool.commonPool-worker-1
Combining 3 and 4 in thread main
Combining 3 and 7 in thread main
10
An image which depicts this flow of execution is shown below.
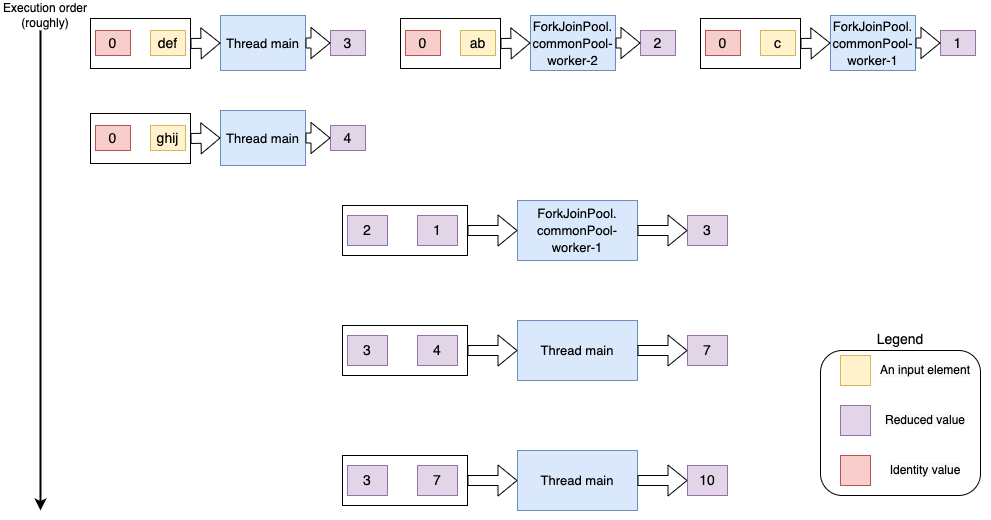
We can see three threads starting the reduction process in parallel (threads main, ForkJoinPool.commonPool-worker-1 and ForkJoinPool.commonPool-worker-2). Each of them gets the identity value and a string element from the stream. Now, we have end up with a bunch of values of type T (partial results). The stream pipeline uses the combiner function to merge or combine these computed partial results.
In this example, all the input elements from the stream were paired with the identity element (0) during processing. However, this will not always be the case. When we have a large number of elements, not all elements will be paired with the identity element. The accumulator function thus can be called with a partial result and an input element (as shown below).
Accumulating 0 and string 'def' in thread main
Accumulating 0 and string 'ab' in thread ForkJoinPool.commonPool-worker-2
....
Accumulating 3 and string 'cd' in thread main
....
Combining 5 and 2 in thread main
....
Moving the accumulator logic as a map operation
We can use a map operation and the first form of reduction (which uses an identity element and an accumulator function) instead of the third variety of Stream#reduce. In the third variety of the Stream#reduce, the accumulator took the partial result (of type U) and a stream element of type T and returned an element of type U. It does both a mapping operation and accumulation. Instead, we can move the mapping operation out of the accumulator as a separate map operation on the Stream.
In the above example, the accumulator took an Integer and a String and returned the result of adding the string’s length to the partial result. Instead, we could do:
List<String> strings = List.of("ab", "c", "def", "ghij");
int length = strings.stream()
.map(String::length)
.reduce(0, Integer::sum);
System.out.println(length); //10
Or, in this case, you can even use mapToInt and generate an IntStream as well.
System.out.println(strings.stream()
.mapToInt(String::length)
.sum()); //10
However, sometimes using the third version of reduce is helpful when we have to know the previous partial result to compute the next.
Conclusion
This concludes the post on Java Stream reduce operation. We learnt about the three versions of Java Stream reduction with examples in this post. First, we understood the properties a reduction function must have viz., should be associative, stateless and shouldn’t interfere with the stream data source. Next, we dived deep into each of the overloaded reduce() operation and also explored how it would work when used on a parallel stream.
Also take a look at other posts on Java-Stream.