Introduction
In Java, a Map data structure is an object that maps keys to values. A Map cannot contain duplicate keys. Each key can map to at most one value. HashMap is one of the implementations of the Map interface. It is a hash table based implementation where it uses the hash code of the keys to store the objects.
In this post, we will see how a HashMap works in java. We will see how get and put operations are carried out and the importance of having a good hash code method.
HashMap basics
We use a map as a key-value store. The values are stored against a key. Different values written into a map for the same key will overwrite the previous value for that key. When retrieving values from the map, we typically query the map to return the value for a key (though it is possible to get all the values without supplying a key).
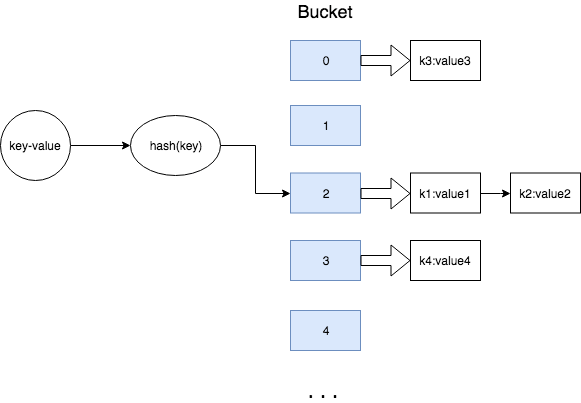
Hashmap has an array of buckets. Each bucket represents a hash value. There can be more than one object stored against a bucket.
To store a given key-value, hashmap has to first determine which bucket the value must go into. Hashmap hashes the passed key using a hash function. The result of this hash function determines the bucket. Next, the value will go into the linked list of items stored against the bucket.
Item object
For the rest of the discussion, we will use the Item object as the key of our hashmap. We will use the Hashmap to store some statistics for each Item. We are not really interested in the data type of the value. Hence, we will just keep it to an Integer for simplicity.
import java.util.Objects;
public class Item {
private final String name;
private final Integer id;
public Item(String name, Integer id) {
this.name = name;
this.id = id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Item item = (Item) o;
return Objects.equals(name, item.name) &&
Objects.equals(id, item.id);
}
@Override
public int hashCode() {
return Objects.hash(name, id);
}
}
The Item class has the name and id of the item. It has equals and hashCode method overridden. We consider two Items to be equal if and only if the id and the name matches. Similarly, hashCode method is computed by considered both the fields.
Our HashMap declaration is
Map<Item, Integer> items = new HashMap<>();
HashMap put operation
To insert an item into the hashmap, we pass the key and the value to the put method. The hashmap does two things - determining the bucket and storing the value
Determining the Bucket:
- It finds the hash of the key. The hash value here is the same as what the (Item) object’s hashCode method returns. This hash value will determine which bucket will hold this key-value pair (being inserted).
- The return type of hashCode is an int. There are 2^32 possible int values. It is not feasible to have as many buckets. Hence, it does a modulo division (divide and consider the remainder) by the number of buckets. The result will be the bucket to which the hashmap will store the value.
Storing the value:
From the modulo operation, it can be evident that more than one object can map to the same bucket. This is because we are mapping all possible integer values to a finite set of ints (buckets). Hence, all the values/key-value pairs are stored as a linked list against a bucket. The value stored in the bucket will have both the key and the value. Let us call each value that is stored a node.
- To insert the current value, it finds the correct position in the list by scanning through the list and calling equals on the current key and the key corresponding to a node.
- If they match, the node is replaced and hence the value of the existing key from the node would be updated with the new value.
- Else it moves to the next node.
- If the end of the list is reached and there was no node corresponding to the inserted key, a new node is created that represents the key-value inserted and is linked from the last node.
Illustration of HashMap put
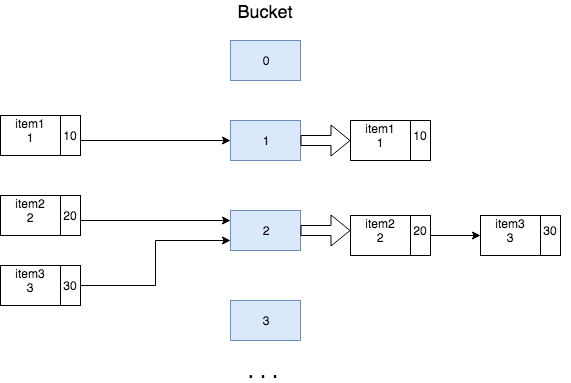
Let us put three items into the hashMap
items.put(new Item("item1", 1), 10);
items.put(new Item("item2", 2), 20);
items.put(new Item("item3", 3), 30);
Assume item1 maps to bucket 1 and item2 and item3 map to bucket2.
Since item1 is being inserted for the first time, it is inserted as the first node of the linked list corresponding to bucket 1.
The same is true for item2 corresponding to bucket 2.
When item3 is inserted, it checks if the first item in the linked list of bucket 2 (item2) equals the current item (item3). It does not. Hence, it is added as the last item in the list.
After inserting the three items, the hashmap will look like
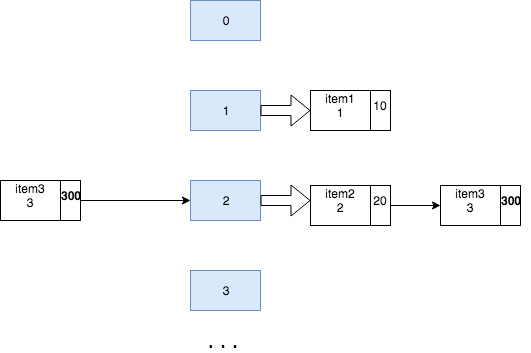
Now, let us overwrite item3 with new value.
items.put(new Item("item3", 3), 300);
As earlier, item3 will map to bucket 2. Now, on scanning the list at bucket 3, the equals check will return true when comparing the current item (item3, 3) with the item associated with the node (item3, 3) and hence the node will be replaced resulting in value overwrite.
HashMap get operation
To retrieve an object from the map, a similar exercise is done.
- Firstly, it finds the hash of the key to locate the bucket.
- Secondly, it scans the linked list of nodes, calling the equals method to find if the node’s key equals the current key.
- In case a match is found, the value of that node is returned.
- If no match is found, it moves to the next node.
- If end of list is reached, the key is decided to not exist and null is returned.
Illustration of HashMap get
System.out.println(items.get(new Item("item3", 3)));
It follows a similar process as explained in the put operation. After determining the bucket, it does a sequential scan by comparing the current Item’s key with the Item key of each node. If it finds a match, it returns the value associated with the node. The above get call returns 300.
Time complexity
The time complexity of both get and put methods are O(1) though there is some linear searching is involved. It is considered O(1) asymptotically.
A bad hashCode implementation
What if our Item class’s hashCode always returned the same hash code?
@Override
public int hashCode() {
return 1;
}
This will not have any impact on the functionality or the usage of Item objects as HashMap keys. But this will have a severe impact on the performance.
In this case, all the Item object inserted into the map will go into the same bucket. Hence internally our map degenerates to a linked list. This will result in get and put methods being O(n) as they require a full traversal in the worst case.
Conclusion
In this post, we learn what a HashMap is and how a HashMap works. We looked at the sequence of actions performed by a HashMap when inserting and obtaining values to/from a HashMap We concluded the post by understanding how a bad hashCode implementation can impact our application performance.